Step 01 · Data Collection & Annotation
Building the dataset
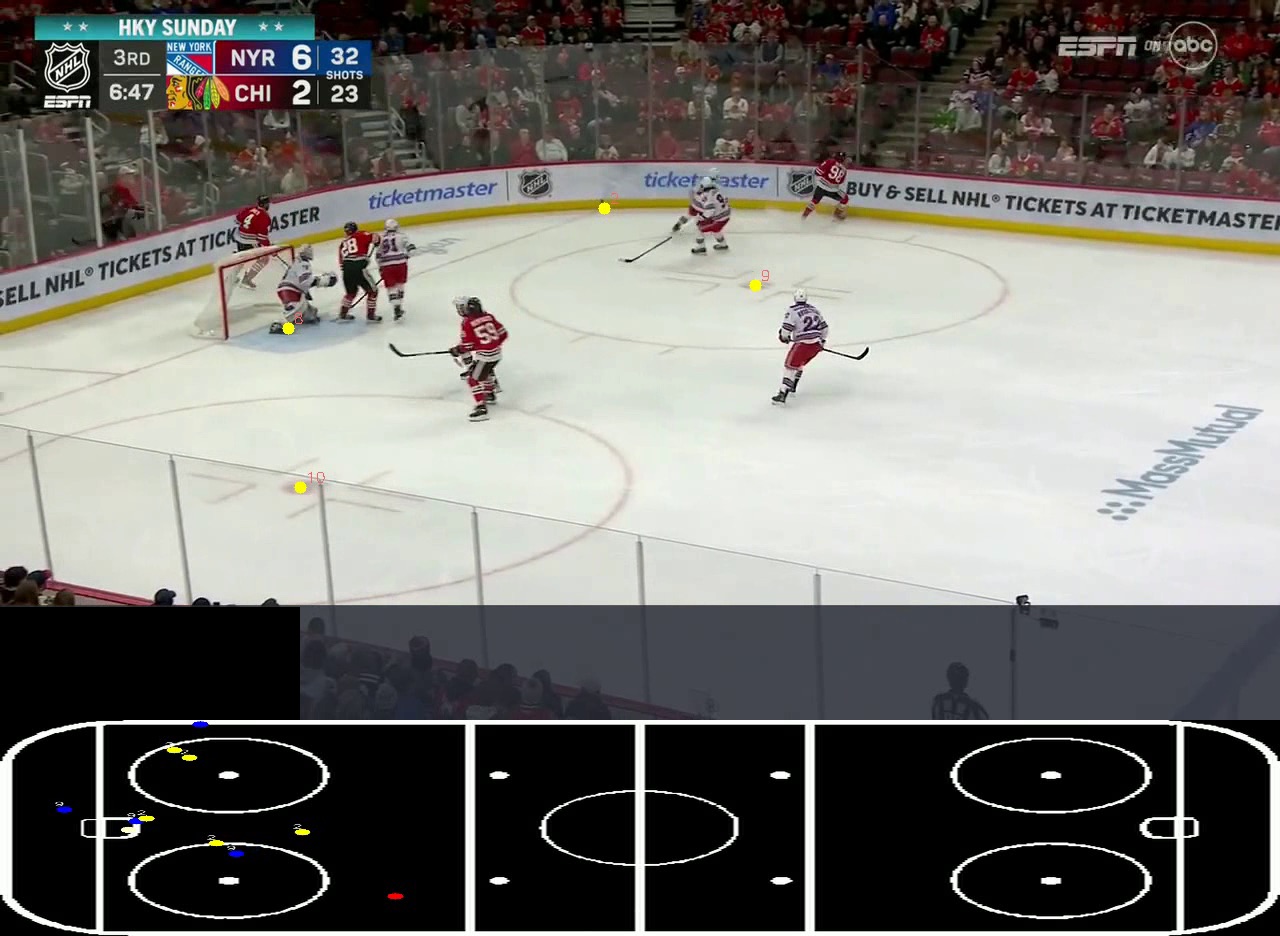
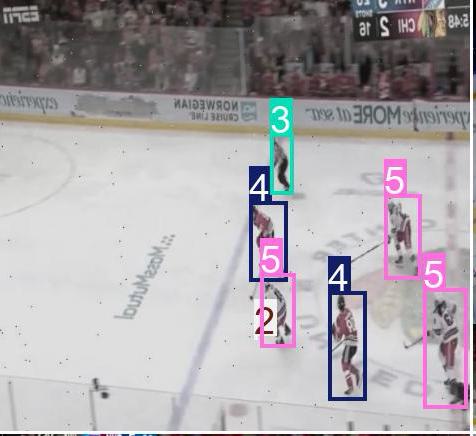
Every model in this pipeline depends on a strong dataset. I manually annotated 10,000 hockey frames — players, pucks, referees, jersey numbers, and key ice features — then ran an augmentation pipeline (rotations, color shifts, brightness, mirroring, motion blur, occlusion) to expand the working set to roughly 60,000 training images.
This augmented set gave the downstream YOLO models enough variation to generalize across broadcast camera angles, lighting conditions, and motion-blurred high-speed plays.